价格
6次/1$
商业使用
允许
API文档资料
模型作者:张吕敏 (Lyumin Zhang)
使用说明
输入一张图像,并像使用Stable Diffusion时那样提供提示语来生成图像。Openpose将自动检测图像中的人体姿态。
模型描述
该ControlNet模型在Stable Diffusion基础上,通过输入图像中的人体姿态图结合文本提示来生成输出图像。
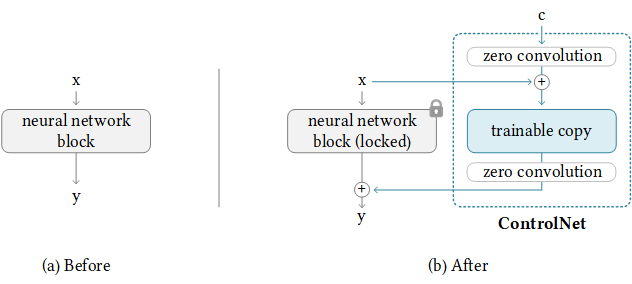
ControlNet是一种神经网络结构,能够扩展预训练大模型以支持提示语之外的额外输入条件。它以端到端方式学习特定任务的条件控制,即使在小训练集(<5万样本)下也具有鲁棒性。其训练速度与微调扩散模型相当,甚至可在个人设备上完成。若配备强大算力集群,还能处理海量训练数据(百万至十亿级)。通过ControlNet,Stable Diffusion等大型扩散模型可新增边缘图、分割图、关键点等条件控制能力。
其他ControlNet变体
ControlNet可通过多种方式改造Stable Diffusion的输出效果。以下是几种不同方案,均需同时输入图像和提示语,其差异在于对输入图像的处理方式:
基于绘图的图像生成 涂鸦控制:https://replicate.com/jagilley/controlnet-scribble
基于输入图像的人体生成 人体姿态检测:https://replicate.com/jagilley/controlnet-pose
保留输入图像整体特征 边缘检测:https://replicate.com/jagilley/controlnet-canny HED图:https://replicate.com/jagilley/controlnet-hed 深度图:https://replicate.com/jagilley/controlnet-depth2img 霍夫线检测:https://replicate.com/jagilley/controlnet-hough 法线图:https://replicate.com/jagilley/controlnet-normal
引用文献
@misc{https://doi.org/10.48550/arxiv.2302.05543,
doi = {10.48550/ARXIV.2302.05543},
url = {https://arxiv.org/abs/2302.05543},
author = {Zhang, Lvmin and Agrawala, Maneesh},
keywords = {Computer Vision and Pattern Recognition (cs.CV), Artificial Intelligence (cs.AI), Graphics (cs.GR), Human-Computer Interaction (cs.HC), Multimedia (cs.MM), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Adding Conditional Control to Text-to-Image Diffusion Models},
publisher = {arXiv},
year = {2023},
copyright = {arXiv.org perpetual, non-exclusive license}
}
使用量分析
controlnet-pose 使用统计
replicate - 调用数据分析